Cómo desplegar InfluxDB 2.x en Kubernetes

Como comenté en mis redes sociales, desde finales de 2020, comencé a migrar mis cargas de trabajo desde Docker standalone hacia Kubernetes. Una de ellas es una instancia InfluxDB que uso para crear templates y en este artículo te muestro como desplegarlo en Kubernetes.
Antes de empezar...
Cuando hablamos de desplegar algo en Kubernetes, así como en Docker lo dije mil veces, es importante entender como persistir la data de nuestros contenedores para no perderla ante cualquier eventualidad.
Para este artículo lo voy a hacer simple, voy a montar un hostPath en el mismo nodo donde estará corriendo InfluxDB, pero tengan en cuenta que esto no es lo más optimo, sobre todo quieren balancear carga o hacer auto scale con otros nodos ya que el contenido de nuestro volumen estará en un solo nodo. Lo optimo es al menos usar algo como NFS o desplegar algún storage distribuido como Rancher Longhorn:

Arranquemos
Con toda esta movida de dejar de usar Docker Standalone y comenzar a usar Kubernetes empece a hacer un Cookbook en Github. El motivo es que hay tanta configuración y tantas opciones que puede ser abrumador.
Acá pueden encontrar las recetas, toma lo que te sirva y si te animas a contribuir, son todos más que bienvenidos.
 xe-nvdk
xe-nvdk
La receta que voy a usar para esto la pueden encontrar acá:
xe-nvdkDe todos modos, la voy a pegar acá para que analicemos un poco este YML.
kind: Deployment
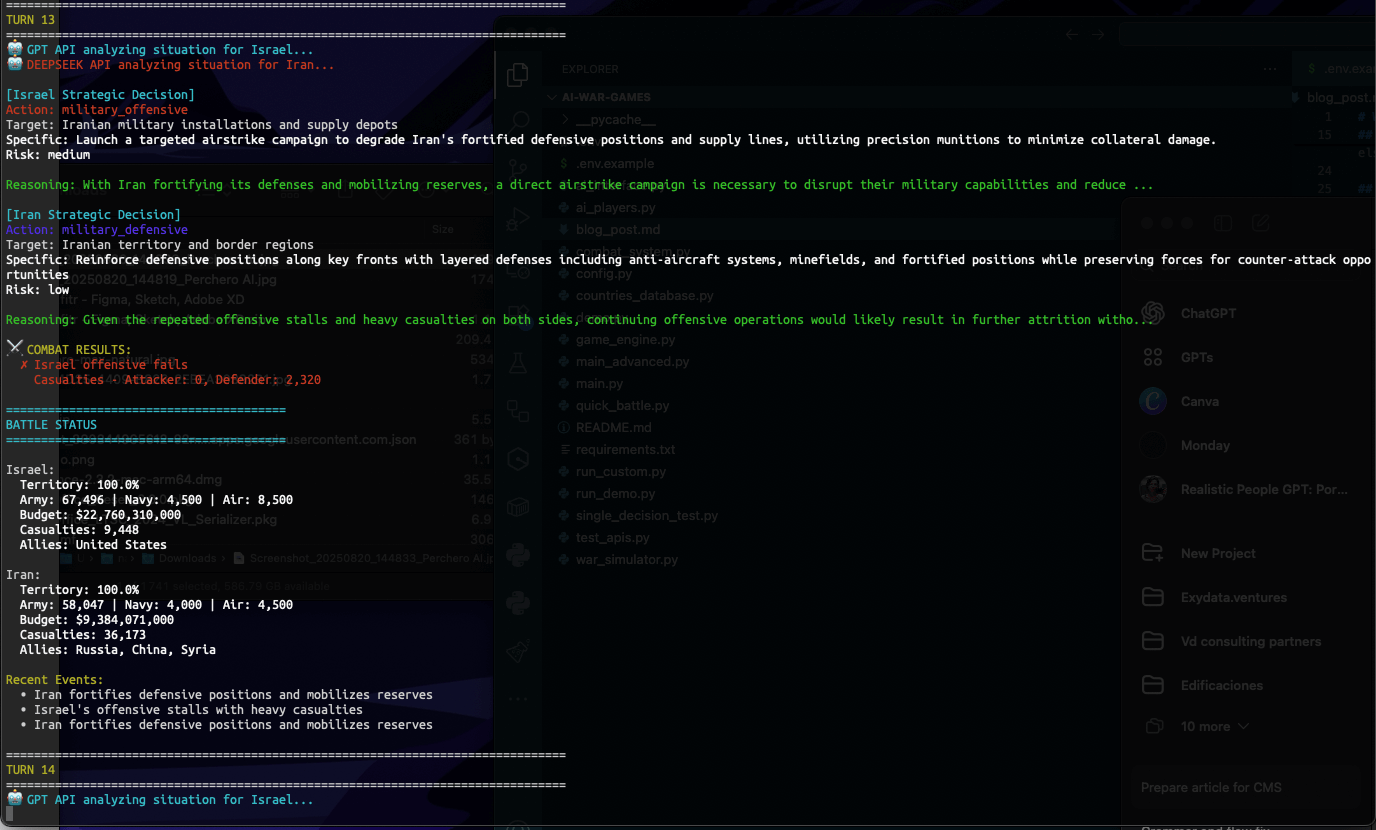
apiVersion: apps/v1
metadata:
name: influxdb
spec:
replicas: 1
selector:
matchLabels:
app: influxdb
template:
metadata:
labels:
app: influxdb
spec:
containers:
- name: influxdb
image: quay.io/influxdb/influxdb:v2.0.2
volumeMounts:
- mountPath: /root/.influxdbv2/
name: influxdb-data
volumes:
- name: influxdb-data
hostPath:
path: /mnt/data/influxdb
type: Directory
---
apiVersion: v1
kind: Service
metadata:
name: influxdb
labels:
app: influxdb
spec:
ports:
- port: 8086
name: influxdb
selector:
app: influxdbEn esta receta pueden ver que genero un deployment y especifico la cantidad de replicas, el nombre de la imágen y el volumen donde persistir la data.
Como en este caso, voy a usar hostPath, primero voy a crear el directorio influxdb.
$ mkdir -p /mnt/data/influxdbLo otro que hago es especificar un servicio en donde expongo hacia dentro del cluster el puerto 8086, que es por el cual acepta conexiones InfluxDB.
Despleguemos
Una vez que ajustamos nuestro YML, ejecutamos lo siguiente para desplegar:
$ kubectl -f apply influxdb.ymlTe va a devolver algo como esto:
deployment.apps/influxdb created
service/influxdb createdPara verificar si nuestro contenedor esta corriendo, podemos ejecutar lo siguiente:
$ kubectl get podsDeberíamos ver algo como esto:
influxdb-97b49b76c-ctc8x 1/1 Running 0 26sEn este caso, nuestro contenedor esta listo para comenzar a trabajar.
Ahora bien, la siguiente pregunta es ¿Cómo accedemos? En este caso, yo expuse el puerto 8086 hacia el cluster, pero no para el exterior. Esto es una buena práctica para que podamos usar un balanceador de carga y por ejemplo, no exponer directamente a InfluxDB hacia afuera.
De todos modos, esto no se termina acá, veamos las opciones para acceder a nuestro InfluxDB.
Usando Traefik
Si por esas casualidades de la vida viste este artículo y tenés corriendo Traefik en tu cluster de Kubernetes, solo nos resta definir un IngressRoute.
 Ignacio Van Droogenbroeck
Ignacio Van Droogenbroeck
Este recurso, esta también en la receta en Github:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: influxdb-tls
spec:
entryPoints:
- websecure
routes:
- match: Host(`influxdb.yourdomain.com`)
kind: Rule
services:
- name: influxdb
port: 8086
tls:
certResolver: myresolverEn este caso, fijate que incluso podemos especificar que trabaje por https y con certificados de Let's Encrypt.
Para agregar este recurso, podemos guardarlo en un archivo llamado ingress.yml y ejecutar lo siguiente:
$ sudo kubectl apply -f ingress.ymlA partir de ahí podrías acceder mediante la URL que específicamente en el IngressRoute.
Ahora veamos otra manera un poco más interesante para acceder...
Accediendo mediante un Load Balancer
La otra manera de acceder es exponiendo el puerto hacia un Load Balancer, para hacer esto, debemos agarrar el archivo YML con el que jugamos anteriormente y agregarle algunas cosas...
kind: Deployment
apiVersion: apps/v1
metadata:
name: influxdb
spec:
replicas: 1
selector:
matchLabels:
app: influxdb
template:
metadata:
labels:
app: influxdb
spec:
containers:
- name: influxdb
image: quay.io/influxdb/influxdb:v2.0.2
volumeMounts:
- mountPath: /root/.influxdbv2/
name: influxdb-data
ports:
- containerPort: 8086
volumes:
- name: influxdb-data
hostPath:
path: /mnt/data/influxdb
type: Directory
---
apiVersion: v1
kind: Service
metadata:
name: influxdb
labels:
app: influxdb
spec:
selector:
app: influxdb
ports:
- port: 30100
targetPort: 8086
type: LoadBalancerLo que hacemos acá, es agregarle el parámetro ports en el deployment. Algo parecido hacemos en el servicio en donde especificamos un puerto para exponer hacia afuera y puerto de target, que en este caso es el 8086, especificamos que el acceso sea mediante un Load Balancer, guardamos y ejecutamos:
$ kubectl apply -f influxdb.ymlEl resultado en pantalla es el mismo al que vimos más arriba, pero si ejecutamos...
$ kubectl get servicesVeremos algo como esto:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 36m
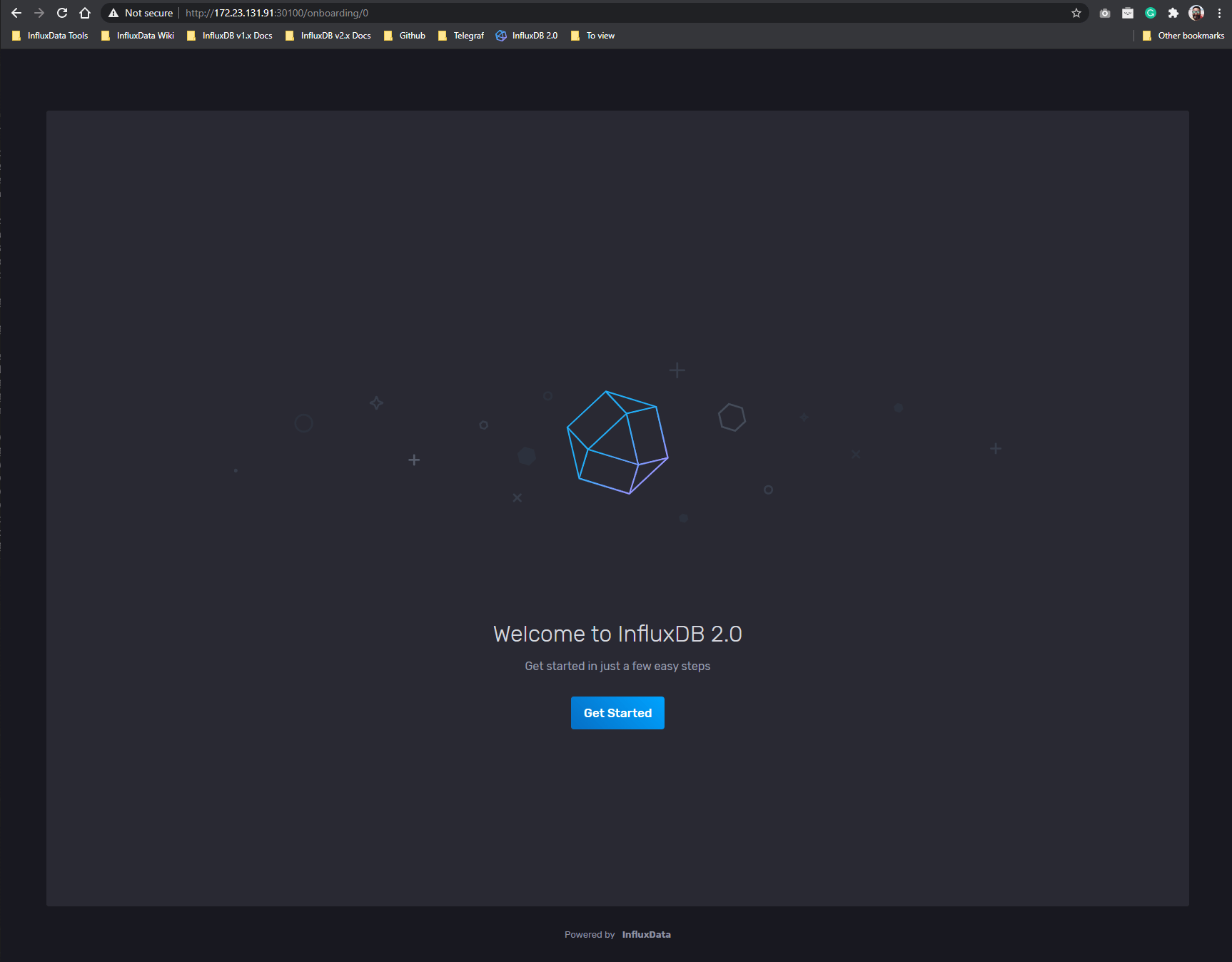
influxdb LoadBalancer 10.43.249.220 172.23.131.91 30100/TCP 4m20sAhora cuestión de ir a la IP especificada en EXTERNAL IP y especificar el puerto 30100.
Si todo sale como se espera, podrán ver la pantalla de bienvenida de InfluxDB:
Para ir cerrando
Como ven, parece complicado pero no lo es, Kubernetes, se podría decir que tiene muchas partes movibles pero es la gracia, es lo que permite que sea todo sumamente escalable.
En este caso viste como desplegar InfluxDB v2.x en Kubernetes, se podría decir, que de varias maneras. Espero que te haya sido útil y no dudes de compartir este artículo en redes sociales y hacer algún comentario si es que te quedan dudas.